这部分总结下传统统计学习的最后一部分内容——非监督学习,非监督学习又称无监督学习,我们前面讲的大部分算法都是需要样本的标签的,通过标签来构造损失函数,进而进行模型学习,但在有的情况下我们并没有数据的标签,这种情况下我们就什么都不能做了么?当然不是,对于无标签数据,我们仍旧可以开展一部分工作,比如:
- 概率模型估计
- 数据降维
- 数据聚类
由于概率模型估计算法在前面已经讲过了(EM算法、概率密度函数估计),这里就不再赘述,本文主要简单介绍下无监督学习问题的思想。
无监督学习思想
无监督学习是从无标注的数据中学习数据的统计规律或者说内在结构的机器学习,主要包括聚类、降维、概率估计,无监督学习可以用于数据分析或者监督学习预处理。
无监督学习使用无标注数据$U = { x1, x_2, \dots, x_N}$学习或训练,其中$x_i,i = 1,2,\dots,N$, 是样本,由特征向量组成。无监督学习的模型是函数$z = g{\theta}(x)$ , 条件概率分布$P{\theta}(z|x)$,或条件概率分布$P{\theta}(x|z)$。其中$x \in X$是输入,表示样本; $z \in Z$是输出,表示对样本的分析结果,可以是类别、转换、概率;$\theta$是参数。
无监督学习是一个困难的任务,因为数据没有标注,也就是没有人为的引导,机器需要自己从数据中找出规律。模型的输入$x$在数据中可以观测,而输出$z$隐藏在数据中。无监督学习通常需要大量的数据,因为对数据隐藏的规律的发现需要足够的观测。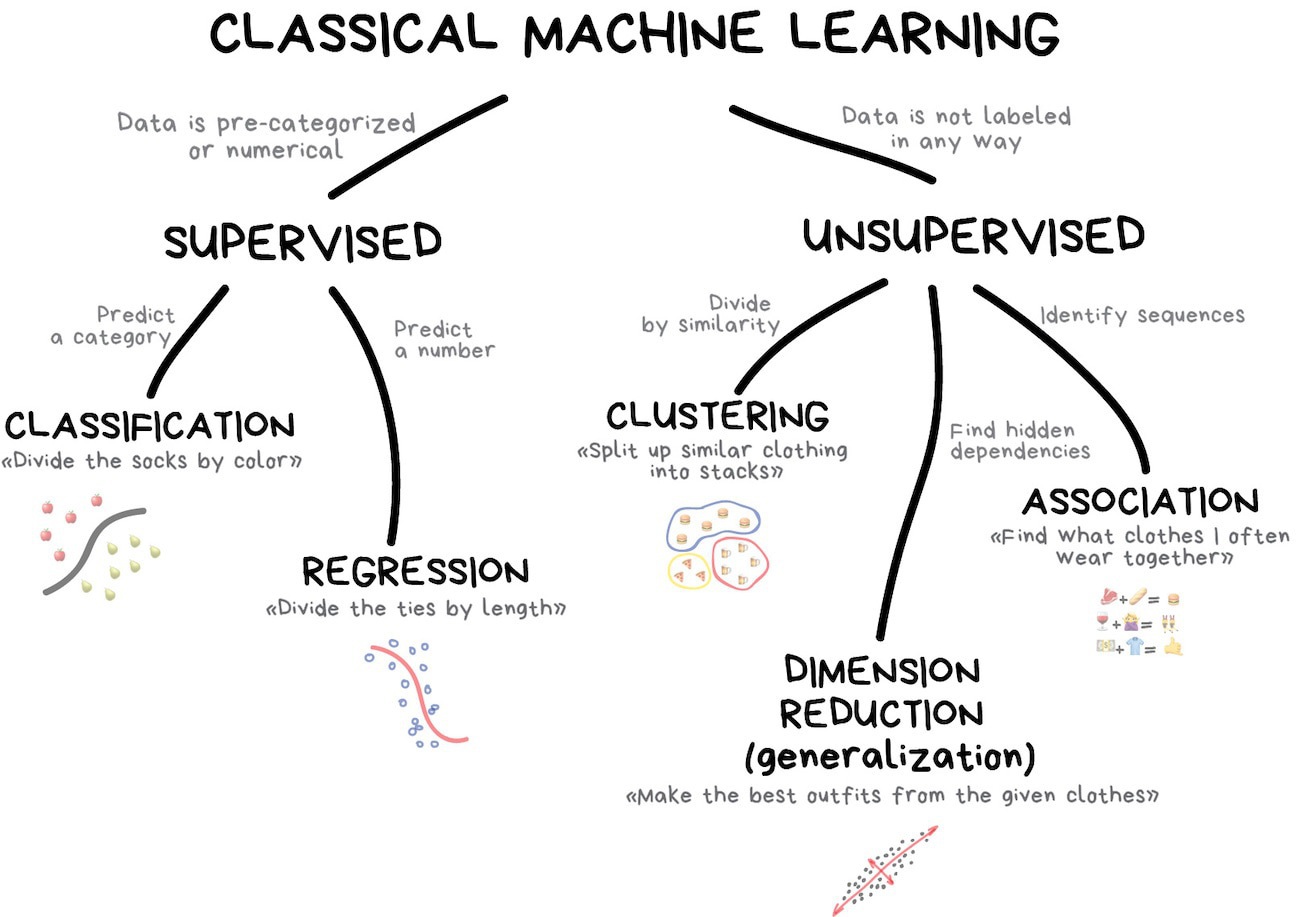
后面将会有两片文章分别介绍降维算法和聚类算法。



