降维是将训练数据中的样本(实例)从高维空间转换到低维空间。假设样本原本存在于低维空间,或者近似地存在于低维空间,通过降维则可以更好地表示样本数据的结构,即更好地表示样本之间的关系。高维空间通常是高维的欧式空间,而低维空间则是低维的欧式空间或者流形(manifold)。低维空间不是事先给定,而是从数据中自动发现,其维数通常是事先给定的。从高维到低维的降维中,要保证样本的信息损失最少。
本文主要介绍四种降维方法:
- 主成分分析法(PCA)
- 多维缩放(MDS)
- 等距特征映射(ISOMAP)
- 局部线性嵌入(LLE)
- 实验部分
在详述各种降维方法之前,我们需要明确这样一件事:
进行降维的过程实际上也是进行特征提取的过程,选择什么样的降维算法取决于我们期望提出哪些特征,比如我们希望提取的特征能够尽可能将样本点区分开来,就可以采用PCA
主成分分析法(PCA)
问题描述
首先我们考虑这样一个问题:
对于正交属性空间中的样本点,如何用一个超平面对所有样本进行恰当的表达?
我们直观上来思考这个问题,若存在这样的超平面,那么它大概具有这样的性质:
- 最近重构性:样本点到这个超平面的距离都足够近
- 最大可分性: 样本点在这个超平面上的投影能够尽可能分开
有趣的是,从上面两个角度出发,能分别得到主成分分析的两种等价推导,PCA算法的推导有一个基本前提:
前提假设:假设样本数据进行了中心化,即$\sum_i x_i = 0$
现在考虑样本空间$R^d$中的一组基${ w1, w_2, \dots, w_d }$, 其中$w_i$是标准正交基向量,$||w_i||_2 = 1, w_i^Tw_j = 0(i \neq j)$,若丢弃新坐标系中的部分坐标,即将维度降低到$d’ < d$,则样本点$x_i$在低维坐标系中的投影是$z_i = (z{i1}, z{i2}, \dots, z{id’})$,其中$z{ij} = w_j^T x_i$是$x_i$在低维坐标系下第$j$维的坐标,若基于$z_i$来重构$x_i$,则会得到$\hat{x}_i = \sum{j=1}^{d’} z_{ij} w_j$,基于上面叙述,我们下面从两个角度来推导主成分分析。
最近重构性
假设有$m$个样本点,则从原样本点到到基于投影重构的样本点$\hat{x}_i$的距离平方的均值为:
其中$W = (w1, w_2, \dots, w{d’})$, 因为我们数据已经做了零均值化,因此$\frac{1}{m}\sum{i=1}^m x_i x_i^T$刚好是样本集协方差矩阵,不妨记$\Sigma = \frac{1}{m} \sum{i=1}^m x_i x_i^T$,因此从这个角度导出来的优化问题为:
最大可分性
若投影向量基选为$W = (w1, w_2, \dots, w{d’})$,则样本点在新空间的坐标为$W^T x_i$,根据最大可分性的定义,我们期望所有样本点的投影能够尽可能分开,也就是说投影后的样本集的方差尽可能大,因为对原始空间的样本点做了0均值化,因此投影后样本集的均值也是零,协方差矩阵则是:
我们的优化目标是向各个坐标轴投影的坐标方差尽可能大,目标函数可以写做:
因此优化问题可以写做:
从优化问题推导来看,从两个角度进行推导,我们得到了相同的优化问题。
优化问题求解
该优化问题是带等式约束的优化问题,考虑采用Lagrange乘子法求解,首先写出Lagrange函数:
需要注意的是,该Lagrange乘子法的写法相当于是将原始优化问题放松了,因为少了$w_i$两两彼此正交的条件,因此我们通过该Lagrange乘子法求得最优解后,需验证其是否满足正交性。 让$L$对$w_i$求偏导并令偏导为0:
由此我们得到了$w_i$应当满足的条件:
上式说明$w_i$应当是矩阵$\Sigma$的特征向量,而其对应的特征值为$\lambda_i$,将该结论回代目标优化式可得:
因此若想让目标函数尽可能大,则应当选取矩阵$\Sigma$的较大的特征值所对应的特征向量作为投影向量。据此我们便可得到PCA算法的流程:
主成分分析法:
输入: 样本集$D = { x1, x_2, \dots, x_m}$, 低维空间维数$d’$
输出: 投影矩阵$W^{\ast} = [w_1, w_2, \dots, w{d’}]$
步骤:
- 对所有样本点进行中心化$xi \leftarrow x_i - \frac{1}{m} \sum{i=1}^m x_i$
- 计算样本的协方差矩阵$\Sigma = \frac{1}{m} X X^T$
- 对协方差矩阵$\Sigma$做特征值分解
- 取最大的$d’$个特征值所对应的特征向量构成投影矩阵
对于主成分分析法,我们可以从多个角度进行理解,从重构损失最小的角度来看,由于原始数据维度很高,但可能其主要的信息仅仅只在几个主成分方向上,因此沿主成分方向进行分解,则可以在保留尽可能多信息的情况下对数据进行降维。从最大可分性的角度来看,将原始空间的样本向主成分方向投影,可以使得样本在这个方向上能够尽可能分开,从这个角度我们对比一下线性判别分析(LDA),LDA是有监督的降维方法,希望不同类别的样本点能够在某个方向上尽可能分开,而PCA则是无监督的降维,是针对整个样本集,期望样本集在某个方向上投影方差尽可能大。
降维维数$d’$的确定
降维后低维空间的维数$d’$通常需要用户事先指定, 或者对于特定任务,通过交叉验证的方法来选取较好的维数,但如果我们从重构损失的角度来看,我们往往期望$\hat{x}$能够尽可能接近$x$,而如何衡量重构效果呢?这里就与信息论相一致,认为一个变量方差越大,则其所包含的信息越多,因此就通过累积方差来横量重构效果,比如$\Sigma$最大的特征值所对应的特征向量为$w_1$,则将原始空间样本点向该特征向量投影,所得到的值的方差为:
而所谓累积方差则是因为我们将原始空间的点向$d’$个主成分方向投影,在这$d’$个方向上的方差和为:
贡献率则是在$d’$个方向上投影的累积方差与向所有$d$个方向投影的累积方差之比:
因此在选择降维维数时,我们也可以从重构贡献率的角度入手,限定贡献率阈值来选取降维维数$d’$。
PCA降维有效性分析
使用PCA将样本点从$d$维降到$d’$维必然会导致信息的损失,这是因为对应于$\Sigma$最小的$d - d’$个特征值所对应的特征向量被舍去了,但有时舍弃这部分信息是必要的,因为:
- 原始空间维度过大,但信息仅仅只在某些主成分方向,通过降维可以便于数据传输,降低传输难度
- 舍弃这部分信息能够使得样本的采样密度增大
- 当数据受到噪声影响时,小的特征值所对应的特征向量往往与噪声有关, 舍弃它们能在一定程度上起到去噪的效果。
多维尺度分析(MDS)
基本思想
PCA降维的出发点是期望能够保留尽可能多的信息,使得投影后方差尽可能大,而多维尺度分析(MDS)的思想则是期望原空间中样本点之间的相似关系能够在低维空间中得到保留。而这种相似性一般是通过距离矩阵来进行度量,假设有$n$个样本,距离矩阵$D$定义为:
其中$d_{ij}$ 表示样本点$i,j$之间的距离,距离度量方法需要结合实际问题来确定。假设原始样本空间为$d$维,降维后空间为$d’$维,则我们期望在降维后的空间里,样本点之间的距离矩阵能够基本与原始空间距离矩阵一样,即将高维空间中的相似关系在低维空间中得到保留。
数学推导
使用MDS进行降维一般需要知道距离矩阵$D$,即原始空间中样本点之间的距离关系是已知的,然后我们期望能够在低维空间能够保持这种距离关系。若我们知道各个样本点的位置,然后计算距离矩阵$D$是比较自然的,现在我们要做的则是逆过程,即根据距离矩阵来还原原始空间中点的坐标,我们首先直观上就可以感到这种还原肯定不是唯一的。
现在我们要做的就是找到一种方法来求解这个逆过程,求解思路则是借助于内积矩阵,而距离矩阵与内积矩阵是有着对应关系的,下面我们来分两部分推导:
- 距离矩阵与内积矩阵的关系
- 内积矩阵与低维空间样本坐标的关系
距离矩阵与内积矩阵
前提:
对样本点做了零均值化,即$\sum_{i=1}^n x_i = 0$
假设原始空间中的样本点为$(x_1, x_2, \dots, x_n)$,其中$x_i \in \mathbb{R}^d$, 那么内积矩阵$B$可以表示为:
其中任意一个元素$b_{ij}$表示为:
而距离矩阵中的元素$d_{ij}^2$在欧氏空间表示为:
由此我们可以推出:
接下来的问题则是考虑如何用$d_{ij}^2$来表示$x_i^T x_i$和$x_j^T x_j$,下面就需要利用原始样本零均值的条件,可以得到:
由此我们便可以得到$x_i^T x_i$ 和$x_j^T x_j$的表达式:
回代前面$b_{ij}$的表达式可得:
为便于表示,做如下标记:
记由$a_{ij}$组成的矩阵为$A$, 则通过上面的推导我们有:
若将$B$表示成矩阵的形式,则有:
内积矩阵与坐标矩阵
上一部分我们推导了距离矩阵与内积矩阵的关系,这一部分讨论下如何由内积矩阵得到坐标矩阵,假设降维后的坐标矩阵为:
则内积矩阵与坐标矩阵应当有如下关系:
同时因为$B$是实对称矩阵,进行特征值分解可得:
此时只要取:
则$X$便能完全重构出距离矩阵$D$,但因为我们的目的是降维,因此只需选取部分维度即可,我们来将$V\Lambda V^T$ 展开:
因此我们只需要取特征值较大的$\lambda1, \lambda_2, \dots, \lambda{d’}$即可较好地重构距离矩阵,因此最终假设要降到$d’$维,则只需要取$B$矩阵的前$d’$大的特征值构成$\Lambda^{\frac{1}{2}}$:
然后取这些特征值对应的特征向量构成$V^T$:
降维后的数据矩阵记为:
总结
MDS算法的降维思想是期望能够在低维空间重构原始样本空间中样本之间的距离关系,上面的推导都是在以欧式距离作为距离度量下推导出的,若选择其他距离方式则没有这样的结论,需要求解相对应的优化问题来迭代优化求解。
等距特征映射(ISOMAP)
流形学习
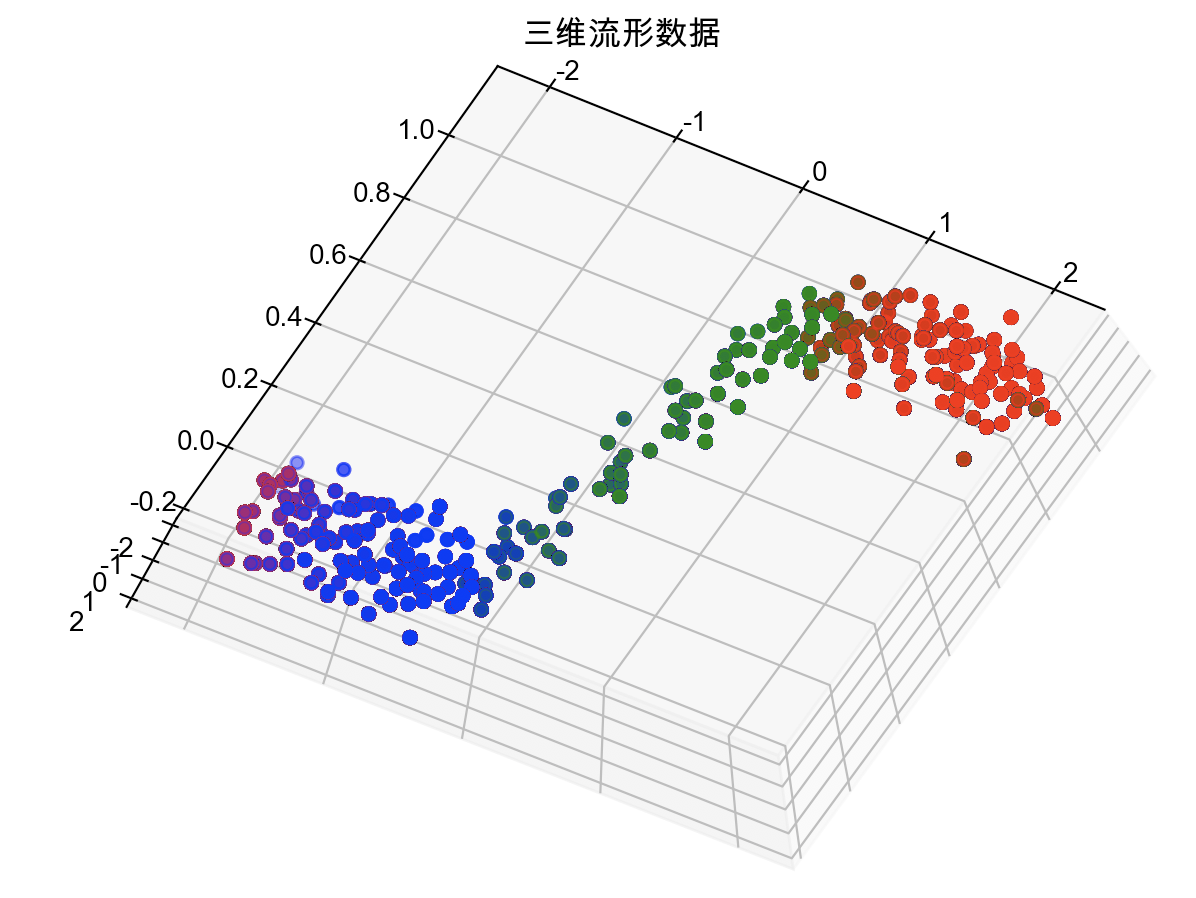
流形学习是一类借鉴了拓扑流形概念的降维方法。“流形”是在局部与欧式空间同胚的空间,换言之,它在局部具有欧式空间的性质,可以用欧式距离来进行距离计算。当低维流形嵌入到高维空间时,则数据样本尽管在高维空间中看起来非常复杂,但在局部仍然具有欧式空间的性质,因此,可以很容易地在局部建立降维映射关系,然后再将局部映射关系推广到全局。下图中作图就是一个二维流形嵌入到了三维空间,若利用流形学习的算法将其降到二维,则如右图所示。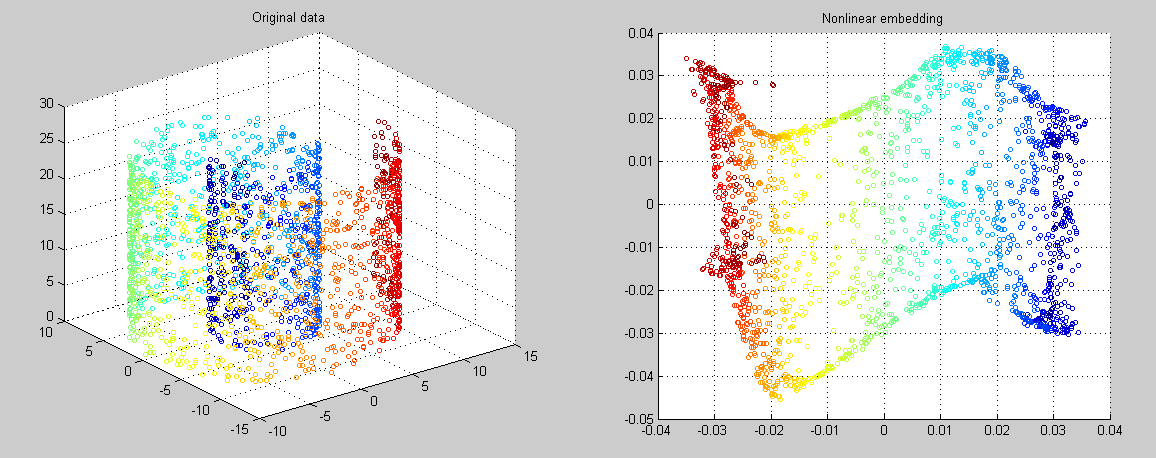
ISOMAP 思想
ISOMAP 的思想其实与 多维尺度缩放(MDS)思想一致,区别在于:
- MDS假设样本点存在于欧式空间中,通过欧式距离来衡量样本的距离。
- ISOMAP假设样本存在于欧式空间的一个低维流形上,在低维流形上,样本之间只有相距较近才可用欧式距离来度量,然后再利用最短路算法构造样本之间的“测地线”距离,即沿流形的最短距离。
因此关键问题就在于如何构建“测地线”距离矩阵,这时我们可以利用流形在局部上与欧式空间同胚的特性,对每个点基于欧式距离找到其近邻点,图中近邻点之间存在连接,而非近邻点不存在连接。于是,计算两点之间测地线距离的问题就变成了计算近邻连接图两点最短路径问题,此时采用dijkstra算法求解即可, 最短路算法流程可以参考如下代码:
def usedijk(dist):
n = dist.shape[0]
for i in range(n):
col = dist[i,:].copy()
while(1):
index = np.argsort(col)[1] # 距离最近的点
if col[index] > 1000:
break
length = dist[i,index] #距离最近的点的距离
for j in range(n):
if dist[i,j] > dist[index,j] + length:
col[j] = dist[index,j] + length
dist[i,j] = dist[index,j] + length
# dist[j,start] = dist[start,j]
col[index] = np.inf
return dist
不过这样需要注意,因为$a$是$b$的近邻点但$b$未必是$a$的近邻点,因此输入的dist矩阵并不对称,如果想要对称,可以通过对称近邻法,即$a$是$b$的近邻的同时将$b$设置为$a$的近邻,下面总结下ISOMAP算法的流程:
ISOMAP:
输入: 样本集$D = (x_1,x_2,\dots, x_n)$,近邻参数$k$, 低维空间参数$d’$
输出: 样本集$D$在低维空间中的投影$X = (x_1,x_2, \dots, x_n)$
算法流程:
- 计算距离矩阵$D$,各个样本点$k$近邻的距离保存,其余设置为无穷,复杂度:$O(n^2)$
- 调用最短路算法计算任意两样本之间的测地线距离矩阵$D’$, 复杂度: $O(kn^2)$
- 将$D’$输入MDS算法,返回得到降维后的数据$X$, 复杂度: $O(n^2)$
局部线性嵌入(LLE)
算法思想
与ISOMAP 试图保持近邻样本之间的距离不同, 局部线性嵌入试图保持邻域样本之间的线性关系,假设在原始空间中,样本点$x_i$能够通过它的邻域样本$x_j, x_k, x_l$重构:
假设我们将样本从原始$d$维空间投影到$d’$维空间,$x_i$及其近邻点在低维空间中的投影点为$x’_i, x’_j,x’_k, x’_l$,我们希望在低维空间中仍能够保留高维空间中的近邻线性重构关系,即:
具体算法思想如下图所示,可以看到所有降维算法的目的都是期望降维后的数据能够与原始空间中的数据尽可能“相似”,选用不同的度量“相似性”的方法也就产生了不同的降维算法。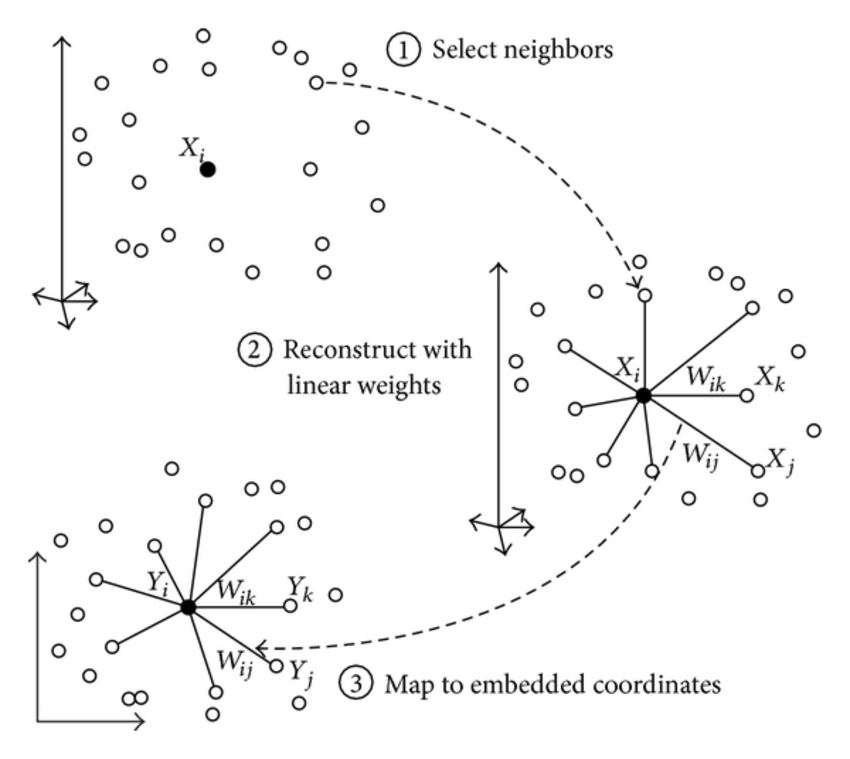
数学推导
从上面分析中可以看出,整个算法流程大致可以分为两步:
- 在原始样本空间中求解权重矩阵
- 在低维空间中重构近邻线性关系
权重矩阵求解
首先假设原始空间中共有$n$个样本$(x1, x_2, \dots, x_n)$, 假设对于样本点$x_i$,其近邻点分别为$x{i1}, x{i2}, \dots, x{ik}$, 则我们期望找到这样一组权重:
使得$||xi - \sum{j=1}^k w{ij} x{ij} ||^2$尽可能小,这样目标函数就可以写做:
我们将目标函数改写一下:
上式中:
若记$S_i = (X_i -N_i)^T(X_i - N_i)$,则优化问题可以写做:
该优化问题可以通过Lagrange乘子法求解,首先写出Lagrange方程:
对$w_i$求偏导可得:
再应用$w_i^T \mathbf{1} = 1$的条件可得:
至此我们便得到了权重系数,为了便于接下来计算,让这些权重系数构成系数矩阵$W$:
其中$w’_i$是将除$w_i$以外的其他样本的系数置零得到, $W$是一个稀疏矩阵。
低维空间投影
我们期望在低维空间$\mathbb{R}^{d’}$中能够保持近邻线性重构关系,也就是说我们期望找到一组样本点:
使得:
能够尽可能小,我们对目标函数做进一步化简:
式中$M = (I-W)(I - W)^T$,同时需要注意到如果我们对降维后空间点的尺度不加限制,那么只要$(z_1, z_2, \dots, z_n)$的模长不断减小,则目标函数就会不断减小,算法不会收敛,同时考虑到我们只是期望在低维空间中保持高维空间中的近邻线性重构关系,如果在标准尺度下能够重构得很好,那么对所有样本点同时进行缩放后依然能够很好地重构,所以优化问题需要加入一个约束条件$Z Z^T = nI$,优化问题最终可以写做:
对于该优化问题的求解依旧是通过Lagrange乘子法,首先写出Lagrange方程:
若将变量矩阵$Z$以行向量形式来表示:
那么Lagrange函数就可以写做:
对$p_i$求导可得:
即$p_i$应当是$M$的特征向量,回代目标函数可得:
又因为我们是期望目标函数最小,因此只需要取矩阵$M$的前$d’$个最小的特征值(非0)作为矩阵$Z$的行向量即可。
实验部分
PCA
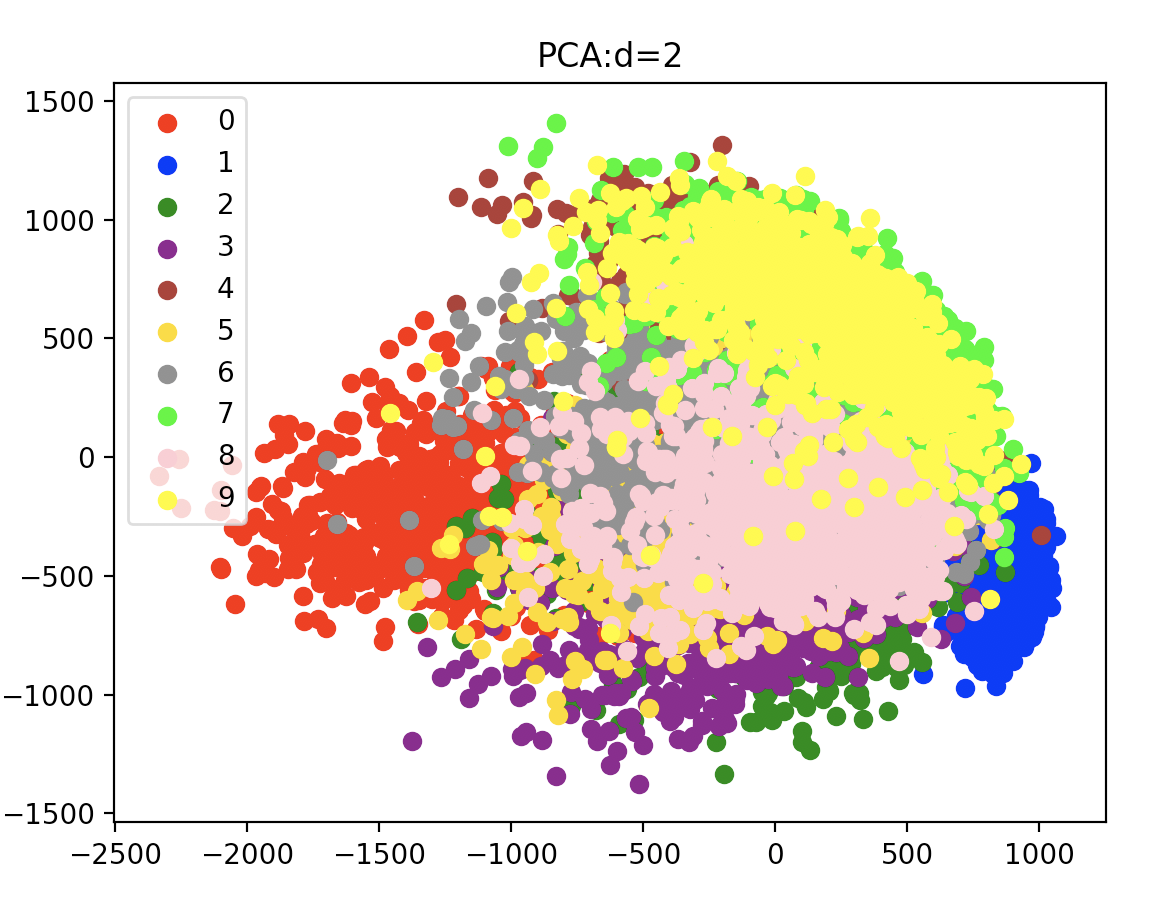
将MNIST手写数字数据集应用PCA从28*28维降到1维和2维的效果图如下: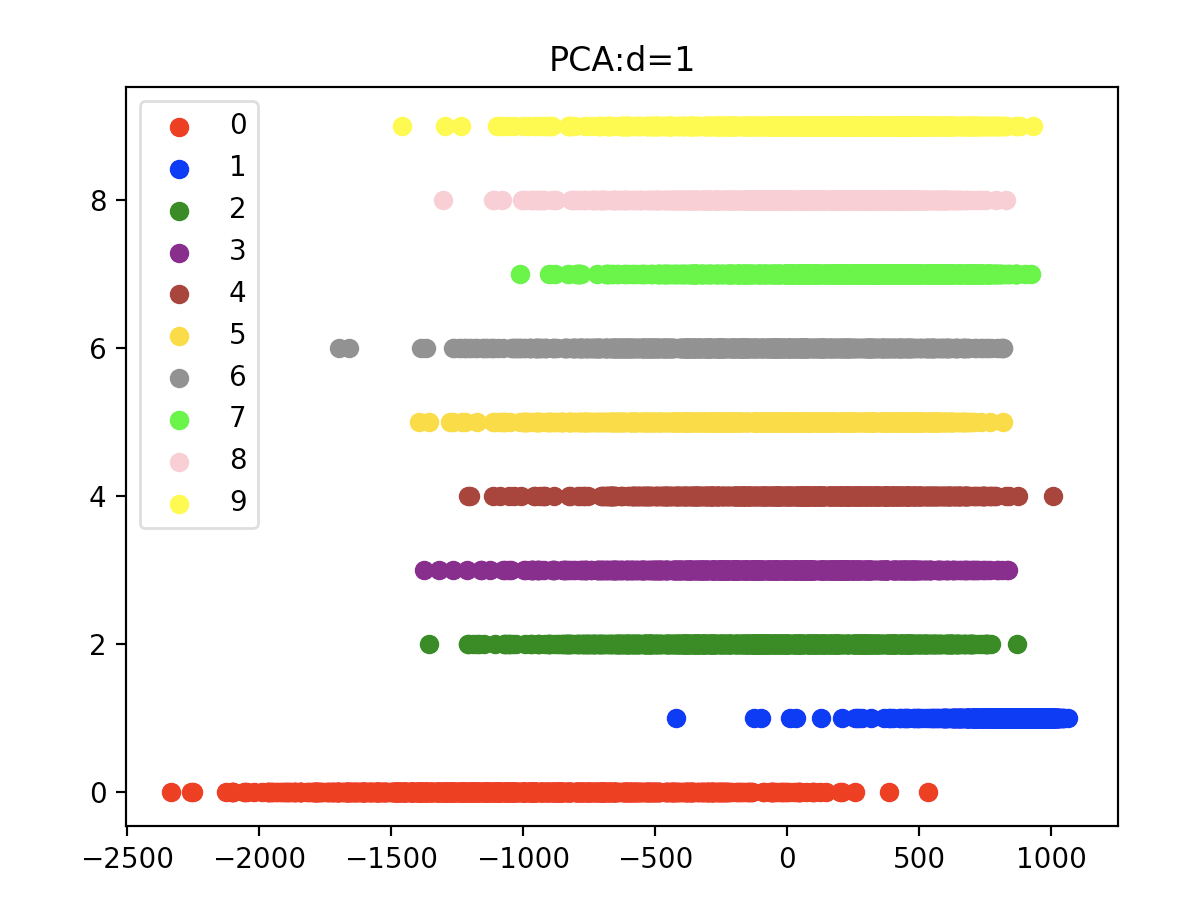
MDS
给若干城市之间的乘车时间信息作为相似度矩阵,然后还原这些城市的坐标。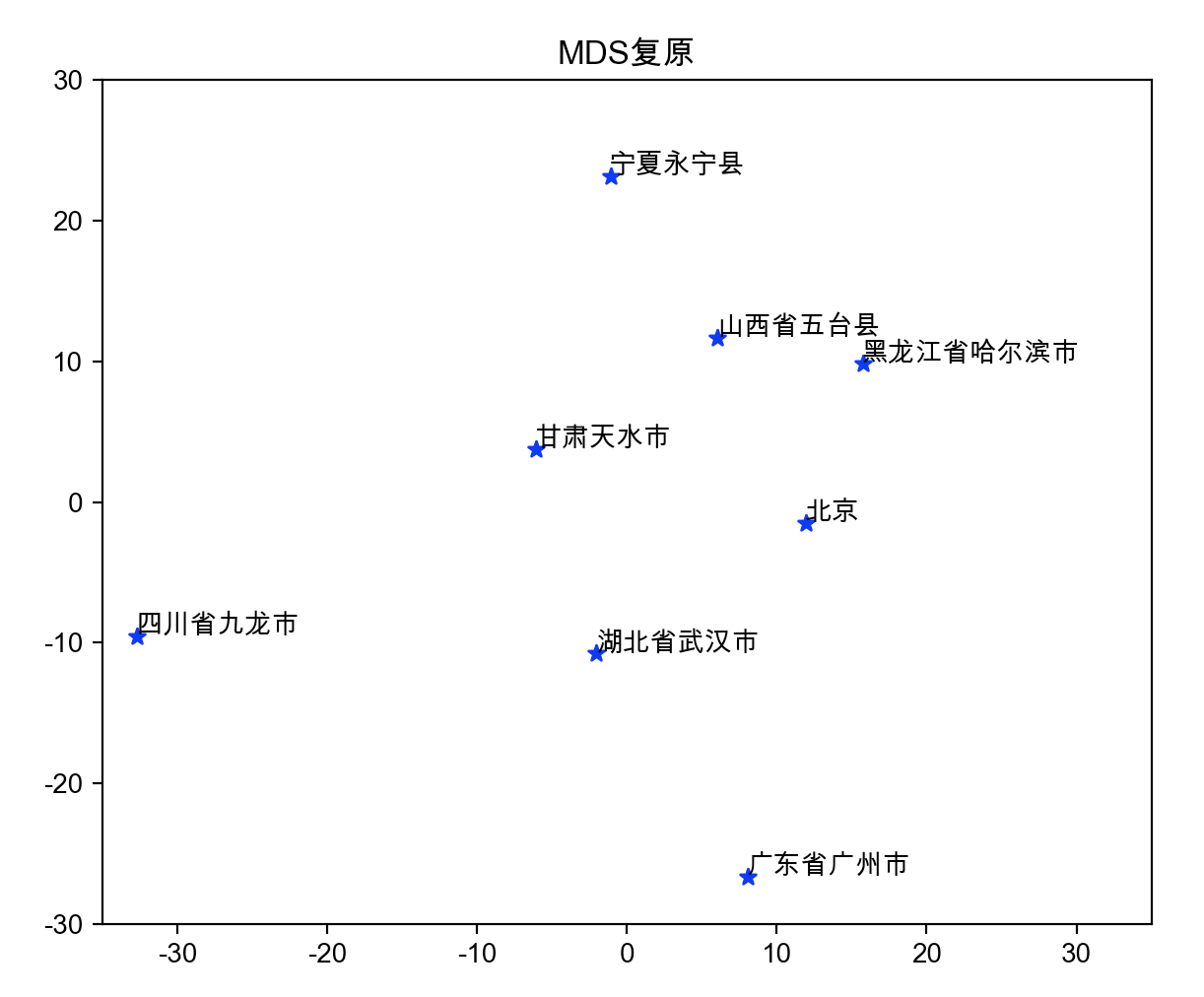
ISOMAP
三维空间中的流形数据降到二维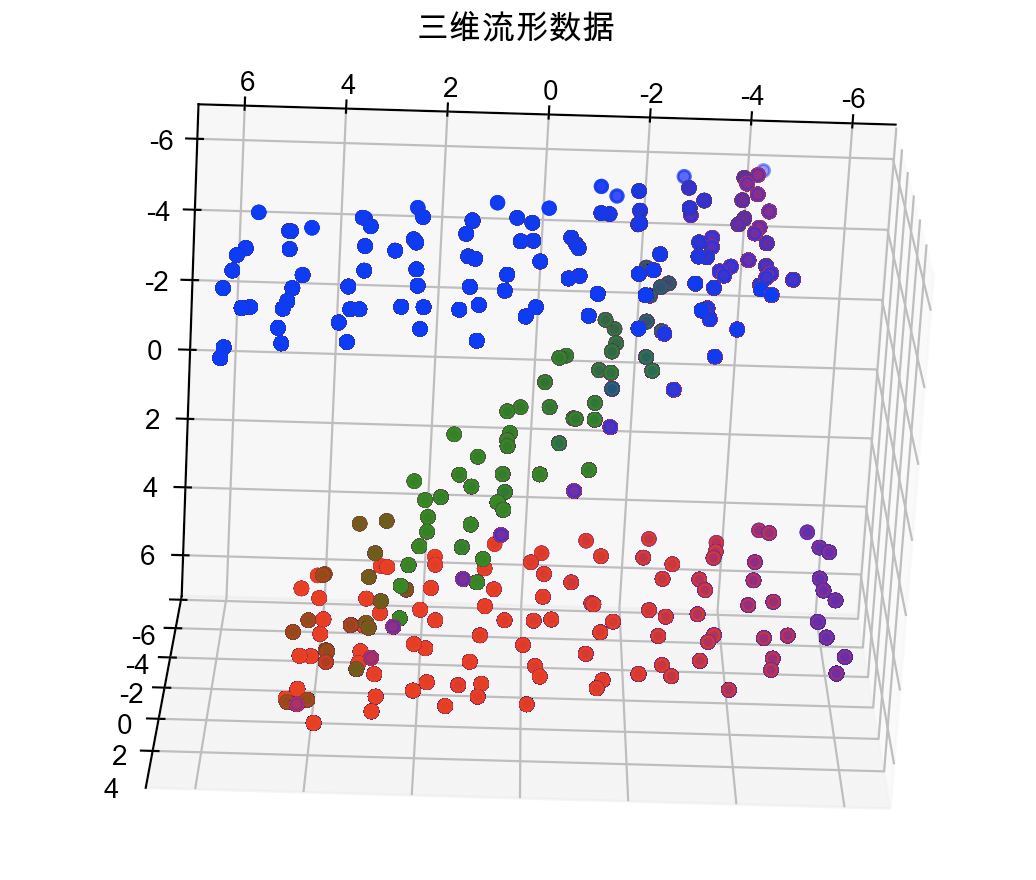
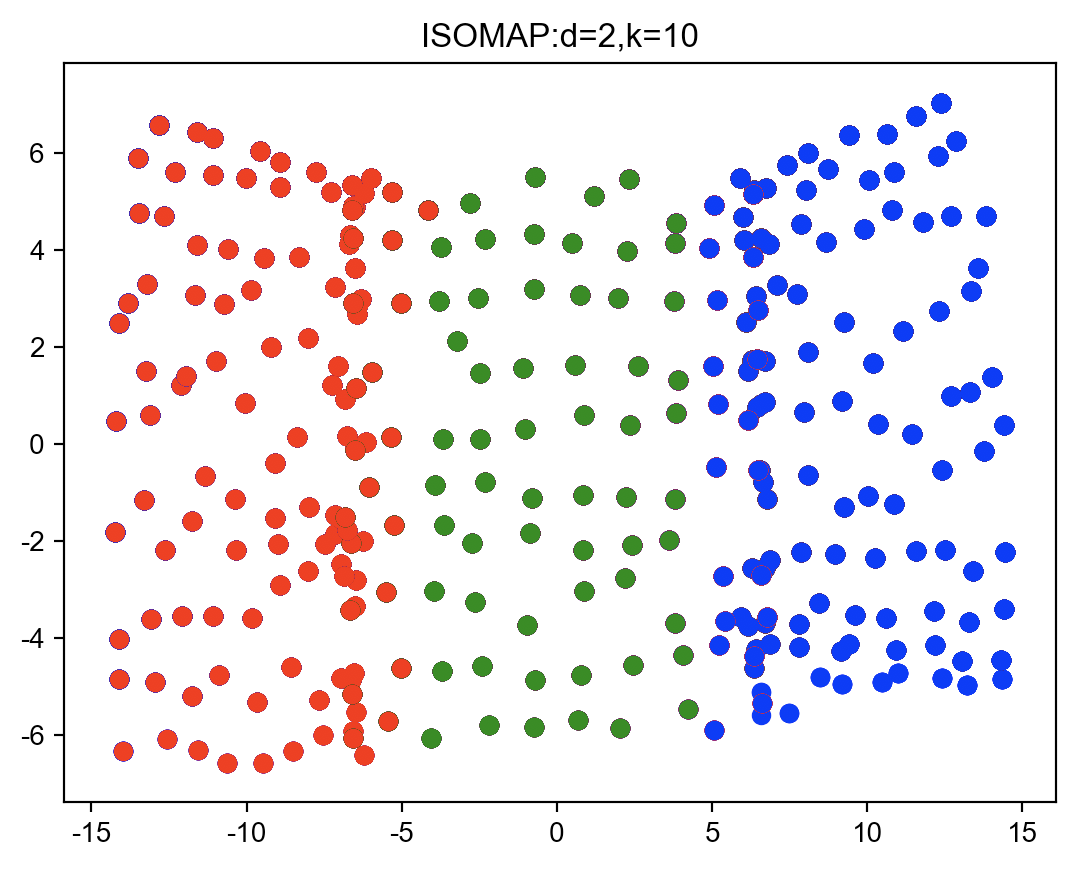
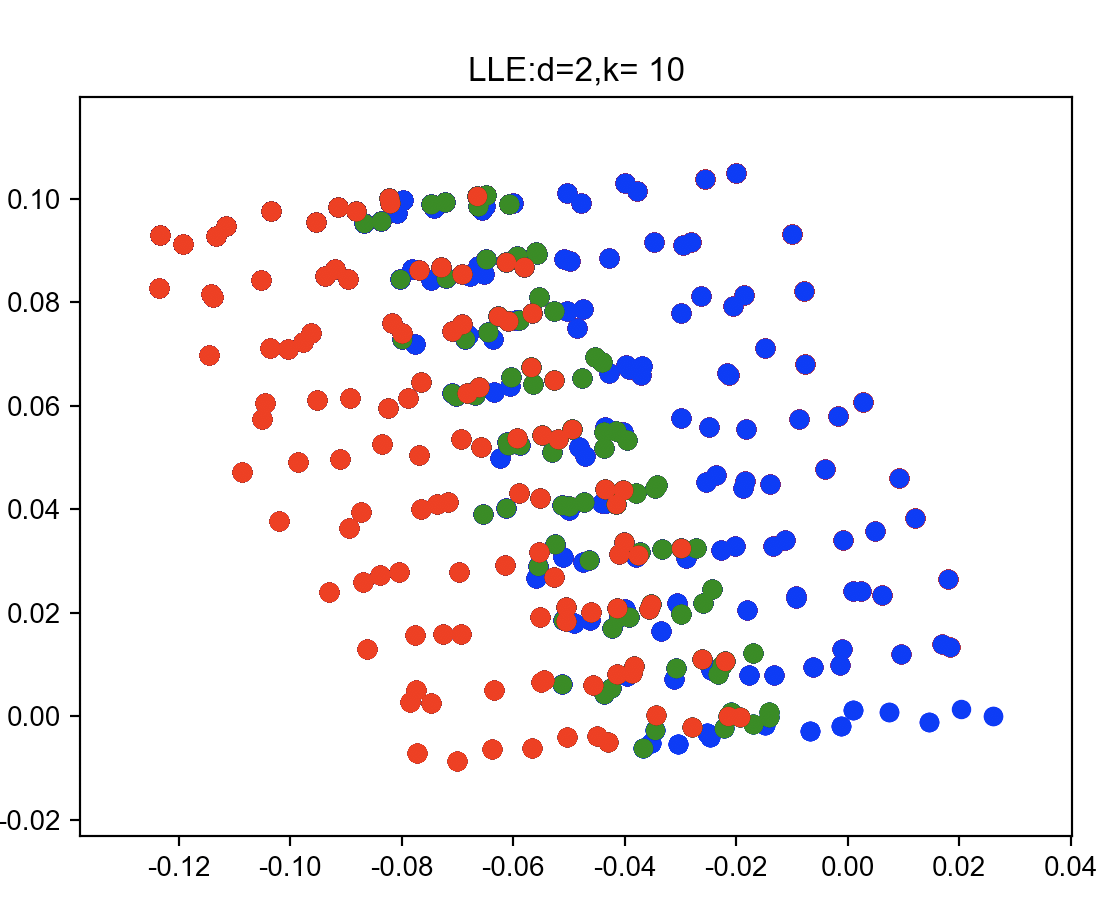
LLE
三维空间中的流形数据降到二维